
文章目录[隐藏]
最近打开 B 站和空间,发现 “谷歌翻译 XX 次” 的视频非常火:
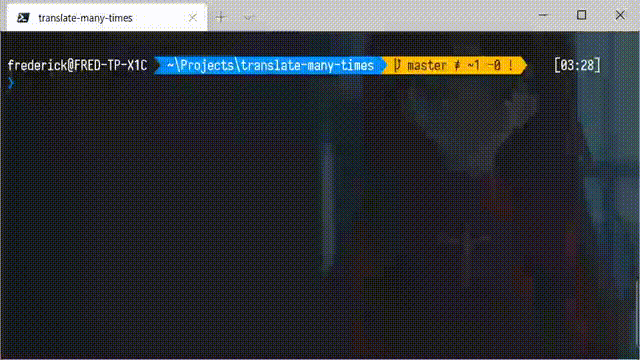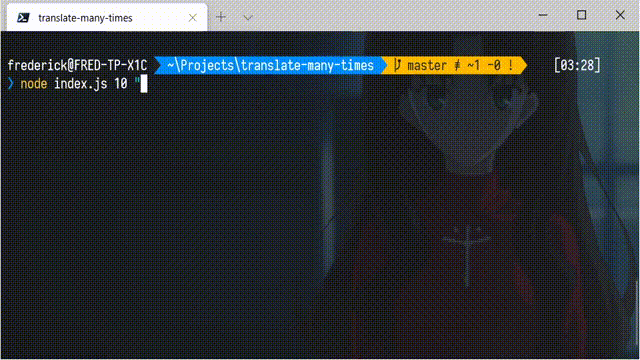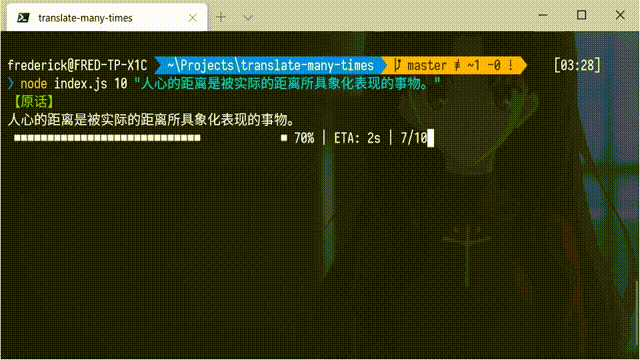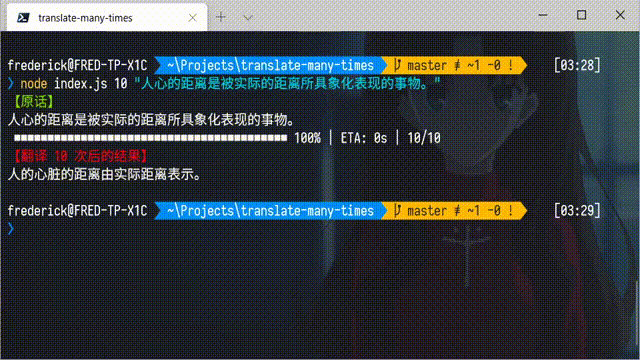
这些视频会用谷歌翻译把一些文本汉译英、英译汉的来回翻译 20 次、50 次甚至更多,然后就会形成一些十分沙雕的效果。有些同学也想自己试一试,但觉得手动来回翻译实在是太累了,问我有没有比较简单的方法。事实上,得益于 Node.js 良好的生态和谷歌翻译的公共 API,只需要很少的代码,就可以完成一个命令行小工具实现这个功能。下面是完成后的效果图: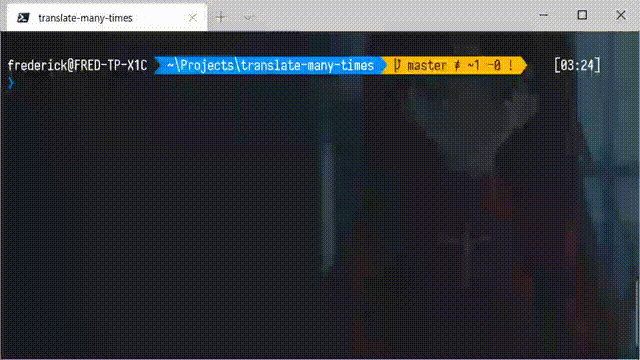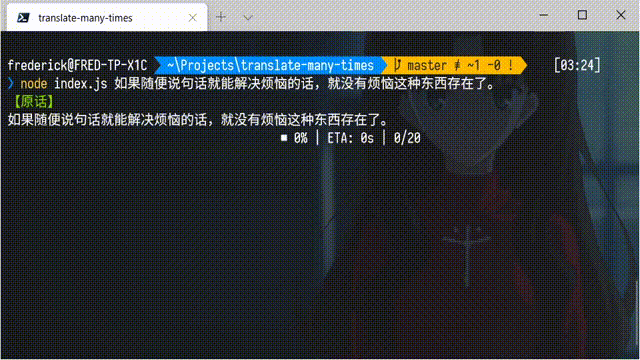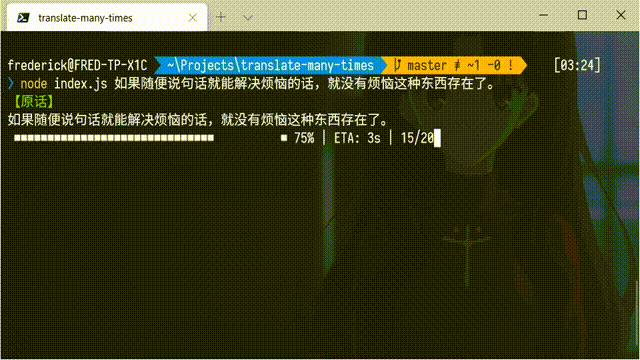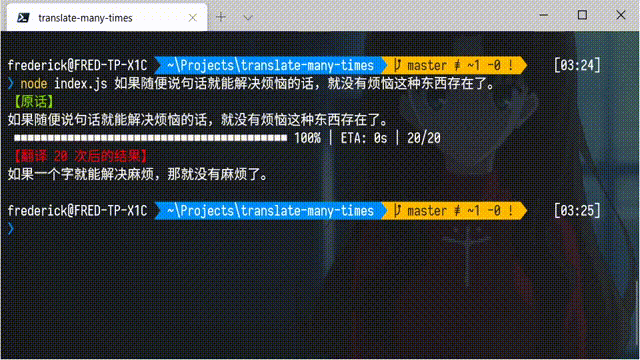 当然,也可以添加参数,指定翻译的次数(默认是 20 次):
当然,也可以添加参数,指定翻译的次数(默认是 20 次):

 而且也可以导入本地文本文件:
而且也可以导入本地文本文件:
 那么,这个小工具是如何实现的呢?请看这篇教程。完整的代码可以查看我放在 Github 上的仓库。
那么,这个小工具是如何实现的呢?请看这篇教程。完整的代码可以查看我放在 Github 上的仓库。
0x00 如何调用谷歌翻译公共 API?
要调用谷歌翻译,首先要分析谷歌翻译的 API。虽然 google.com 在中国大陆无法访问,不过,谷歌翻译专门有一个「中国版」:https://translate.google.cn/
我们进入后,打开开发者工具,侦听网络随便翻译一句话试试看。
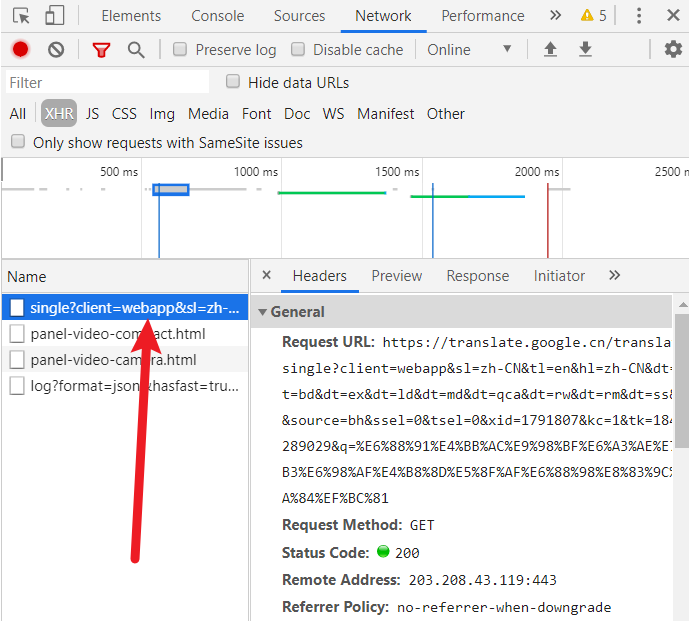
会发现这是一个 Ajax 请求,以 GET 方式访问了一个公开的 Web API,附带了很多的参数(其实必需的参数只有 client、sl、tl、dt、tk、q 这 6 个),然后得到了翻译的结果。
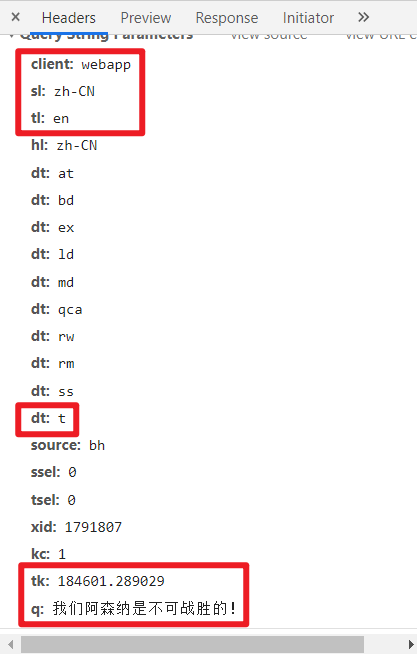
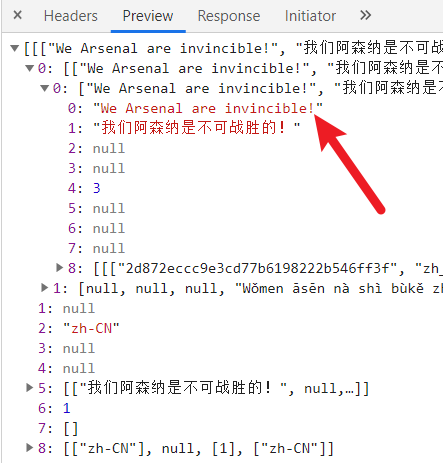
然后就是研究这个 API 如何调用了,其中主要的问题是 tk 这个校验参数,它根据翻译的文本不同每次会发生变化,如果校验失败,就会报错。不过这种公共 API 已经被很多人研究过了,在查询了前人的经验后,就能很方便的知道原来这个 tk 值是根据一个 tkk 值和文本内容联合计算得到的。而这个 tkk 值就在网页的源代码中。
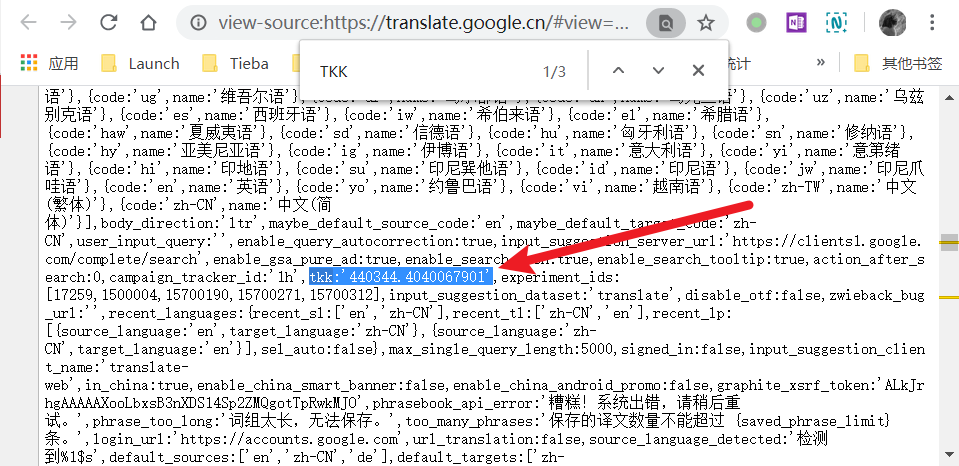
而联合计算的加密函数也已经有人扒了出来,省了很多事。不然我们还需要到 js 源文件中去找这个函数。虽然函数的内容人类不可读,不过只要把它看做一个黑箱,只关心输入和输出就足够了,至于它到底写的是什么其实无所谓了。我将其稍微改写了一下以符合 ESlint 的规范,不报错。
// 这段加密过程的计算代码是被混淆、压缩过的,所以是人类不可读的,直接复制出来使用
const b = (a, b) => {
for (let d = 0; d < b.length - 2; d += 3) {
let c = b.charAt(d + 2)
c = 'a' <= c ? c.charCodeAt(0) - 87 : Number(c)
c = '+' == b.charAt(d + 1) ? a >>> c : a << c
a = '+' == b.charAt(d) ? (a + c) & 4294967295 : a ^ c
}
return a
}
const tk = a => {
let e = tkk.split('.')
let h = Number(e[0]) || 0
let g = []
let d = 0
for (let f = 0; f < a.length; f++) {
var c = a.charCodeAt(f)
128 > c
? (g[d++] = c)
: (2048 > c
? (g[d++] = (c >> 6) | 192)
: (55296 == (c & 64512) &&
f + 1 < a.length &&
56320 == (a.charCodeAt(f + 1) & 64512)
? ((c =
65536 + ((c & 1023) << 10) + (a.charCodeAt(++f) & 1023)),
(g[d++] = (c >> 18) | 240),
(g[d++] = ((c >> 12) & 63) | 128))
: (g[d++] = (c >> 12) | 224),
(g[d++] = ((c >> 6) & 63) | 128)),
(g[d++] = (c & 63) | 128))
}
a = h
for (d = 0; d < g.length; d++) (a += g[d]), (a = b(a, '+-a^+6'))
a = b(a, '+-3^+b+-f')
a ^= Number(e[1]) || 0
0 > a && (a = (a & 2147483647) + 2147483648)
a %= 1e6
return a.toString() + '.' + (a ^ h)
}
在研究明白 API 的使用方法之后,就可以开始编写代码了。
| API 地址 | https://translate.google.cn/translate_a/single |
| 请求方式 | GET |
| 参数:client | 网页版是 webapp,不过后来查到如果填 webapp 会限制查询频率,改成 gtx 就不会限制查询频率了 |
| 参数:dt | 控制返回的数据格式,设置为 t 就可以 |
| 参数:sl | 指定源语言,例如 “zh-CN” |
| 参数:tl | 指定目标语言,例如 “en” |
| 参数:q | 需要翻译的文本 |
| 参数:tk | 校验码,可以根据网页源代码中的 TKK 值与翻译文本内容计算得到 |
0x01 完成核心函数:调用 API 翻译
因为 API 的参数已经很明确了,我们编写的代码步骤就也很明确。首先,需要通过网页源代码获取 TKK 值。然后,根据 TKK 值和翻译的文本计算得到 TK 值。接下来,填入参数,调用 API 就可以了。
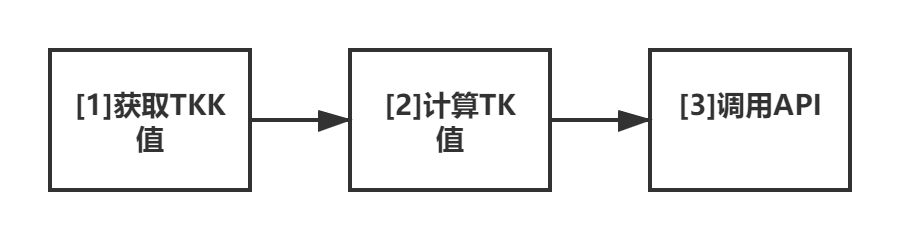
如何获取 TKK 值呢?很简单,拉取网页源代码,然后用正则表达式匹配一下就可以了。可以将其封装为 getTKK 函数。因为只是一个简单的小工具原型,所以这里的 I/O 操作我们没有处理异常,之后所有的 I/O 操作同理,都 “假定其可以顺利执行”。
我一般使用 got 这个包来处理网络相关请求,具体的调用方式可以查看文档,这里不再赘述。
/**
* 从网页中获取谷歌翻译的 TKK 值
*
* @param {string} text 源文本
* @param {string} sl 源语言
* @param {string} tl 目标语言
* @returns 获取的 TKK 值
*/
async function getTKK(text, sl, tl) {
const url = `https://translate.google.cn/#view=home&op=translate&sl=${sl}&tl=${tl}&text=${text}`
const res = await got(url)
const tkk = res.body.match(/tkk:'(.+?)'/)[1]
return tkk
}
在获取了 TKK 值之后,我们需要调用刚才提到的那个混淆、压缩过的 TK 值计算代码,并将这个过程封装为一个 getTK 函数。
/**
* 获取谷歌翻译的 TK 值
*
* @param {string} text 源文本
* @param {string} sl 源语言
* @param {string} tl 目标语言
* @returns 获取的 TK 值
*/
async function getTK(text, sl, tl) {
const tkk = await getTKK(text, sl, tl)
// 这段加密过程的计算代码是被加密过的,所以是人类不可读的,直接复制出来使用
……
(刚才那一段人类无法阅读的计算代码)
……
return tk(text)
}
然后,我们继续把调用翻译 API 的过程封装为一个 translate 函数:
/**
* 调用谷歌翻译 API 翻译文本
*
* @param {string} text 源文本
* @param {string} sl 源语言
* @param {string} tl 目标语言
* @returns 翻译后的结果
*/
async function translate(text, sl, tl) {
// 需要进行 URL 编码,否则回车符无法保留
text = encodeURIComponent(text)
// 获取 API 校验需要的 TK 值
const tk = await getTK(text, sl, tl)
// 这里的 dt=t 是指定返回的内容格式,而设定 client=gtx 可以不触发请求频率阈值,否则请求速度过快很容易 403
const url = `https://translate.google.cn/translate_a/single?client=gtx&sl=${sl}&tl=${tl}&dt=t&tk=${tk}&q=${text}`
const res = await got(url)
// 如果是多行文本,这里会被分割为一个数组,需要重新组合
const result = JSON.parse(res.body)[0]
.map(v => v[0])
.join('')
return result
}
这样,核心代码就完成了。
0x02 站在巨人的肩膀上:调用命令行操作的相关包
命令行界面一般不是单调的文字,也会有色彩,有动画。在文章开始的 GIF 动图中,我们可以看到,在输出文字内容时,有红色和绿色的彩色文字;而在等待翻译的过程中,也有一个进度条动画。而且在调用程序时,还可以自由的输入一些参数,指定翻译次数和翻译的文本。事实上,命令行操作是一个比较复杂的事情,需要考虑不同的操作系统、不同的终端等问题,还好,这些问题已经有前人帮我们处理好了,并将相关代码封装为了包(package),供全世界所有程序员自由的调用。
我一般使用 colors 处理输出彩色字符,cli-progress 控制进度条,minimist 解析输入参数。具体的使用文档可以查看他们的文档,这里不再赘述。
0x03 拼积木!得到最终程序
写程序就像拼积木一样,当我们把不同的功能写好之后,只需把每一部分组合起来就可以了。
;(async () => {
console.log(colors.green('【原话】'))
console.log(`${content}`)
// 初始化进度条
const bar = new cliProgress.SingleBar({}, cliProgress.Presets.rect)
bar.start(time, 0)
for (let i = 0; i < time; i++) {
// 如果是第奇数次,汉译英;如果是第偶数次,英译汉
const lang = ['zh-CN', 'en']
content = await translate(content, ...(i % 2 ? lang.reverse() : lang))
// 更新进度条数值
bar.update(i + 1)
}
// 进度条停止
bar.stop()
console.log(colors.red(`【翻译 ${time} 次后的结果】`))
console.log(content)
})()
这样,我们就完成了整个程序,即使我为了美观已经将一些原本可以写在一行的代码分成了多行,主要的代码也仅仅只有大约 30 行,非常简单。但正如开头的 GIF 动图所示,其实功能比较完备,而且看起来观感也不错。
0x04 改进与增强!
在前文我说过,为了演示思路,所有的 I/O 操作我都没有处理异常,在正式的程序中,异常应该捕获然后做出对应的处理。如果你有兴趣,可以补充上这些代码。
此外,这个程序只能读取并展示结果,并不能把结果再保存。虽然可以通过重定向输出将内容存储到文件中,但还是有点麻烦。同样地,如果你有兴趣,可以补充上这些代码。
另外,在 B 站视频中我们看到很多 UP 主不仅仅只用了谷歌翻译,还有人用了百度翻译、有道翻译、必应翻译等工具,感兴趣的同学也可以试试看调用这些网页服务的 API 接口,实现同样的功能。甚至可以让他们翻译的结果做一个 “对比”。
更进一步,如果你想做一个 UP 主,可以再补充一点文字解析的代码,做到自动加载字幕文件,然后将输出的结果保存为新的字幕文件,这也不会增加特别多的代码量,而且挺有意思的。
……
总之,这个命令行小程序还有很多可以改进、可以增强的地方。
参考文献
[1] °只为大大.Google Translate 的 tk 生成以及参数详情 [EB/OL].https://www.zhanghuanglong.com/detail/google-translate-tk-generation-and-parameter-details,2017-9-25.
[2] WKQ. 爬取 谷歌翻译 [EB/OL].http://weikeqin.cn/2017/11/14/crawler-google-translate/,2019-12-16.
[3] 磐石区.google translate 免费使用 /translate_a/single 接口翻译 [EB/OL].https://blog.csdn.net/panshiqu/article/details/104193607,2020-2-6.
[4] 胖喵~. 破解 google 翻译 API 全过程 [EB/OL].https://www.cnblogs.com/by-dream/p/6554340.html,2017-3-24.
相关文章
Tampermonkey 4.8.41 谷歌浏览器(Google Chrome)版下载
因为谷歌浏览器的官方应用商店被墙了,所以如果您使用谷歌浏览器且没有梯子,在使用SCU URP 助手时会有些不便。因此,本站提供Tampermonkey的crx文件下载,将crx文件下载到本地之后,再打开 Chrome 浏览器「扩展程序」页面,将下载的 crx 文件拖拽到页面即可完成安装。(具体安装过程可以参考《【教程】CRX格式插件不能离线 …

SCU URP 助手「UserScript 版」通用安装教程
如何安装 Userscript 呢?您可以参考当今最大的 Userscript 发布网站 Greasy Fork 首页上的教程,安装一个用户脚本管理器,然后就可以安装 Userscript 了: 第一步:安装用户脚本管理器。教程:https://greasyfork.org/zh-CN 第二步:安装Userscript。 因为脚本昨天(2021-8-13)在 Greasy Fork 上遭到举报,在协商好之前, …

SCU URP 助手「Bookmarklet 版」通用安装教程
(2022-2-14 更新)注意!由于谷歌浏览器安全策略更新,Chrome 94 之后,教务系统无法加载来自外部 HTTPS 源的脚本,因此书签版的 URL 由 CDN 换到了我的服务器上。如果你的书签是在2022年2月14日之前创建的,请删除掉旧的书签,重新拖一次,否则将无法正常使用! 虽然使用 Userscript 是最方便的办法,但有的同学可能不会 …
为 SCU URP 助手增加「计算各种绩点与均分」的功能
期末考试结束了,又到了一年的出分季,若是在过去,算平均绩点和平均分不是什么难事,因为不论是飞扬的绩点计算器还是后来的「We川大」(现川大圈校内通)都很好用。然而,因为教务处这学期的升级改造,帮助了无数学子多年的「川大圈校内通」牺牲了…… 于是我身边的同学们不得不倒退回用Excel或者纸笔计算的原始时代……但作为 …
CSS 的值与单位的常见知识点
在刚刚开始学习CSS的时候,我曾经对值(value)与单位(unit)的相关知识有过一些误解,在使用时也走过一些弯路。今天,我参考MDN回顾了一下自己曾经遇到过的一些有趣的知识点,将其记录在这里,也许也能对初学者有一些帮助。 …
神仙, 你们这套程序,到底要如何才能被用得上, 目前我用起来总是报错,好奇怪, 求助
不得不纠正你文章中一直在强调的错误表达 “这段加密过程的计算代码是被加密过的,所以是人类不可读的”,但这些被处理后的代码明明可以正常阅读和理解,只不过费力点。
1. 加密:是把人类可读的明文经过加密算法和秘钥转换成不可读的密文,密文一定是可以通过秘钥和解密算法转换成明文的,即是可逆的。
2. Uglify: 把代码进行 “混淆” 处理,即把代码中的所有的变量都转换成单个字母,并且保证代码的本身功能不受影响,目的是减小代码文件的大小,同时可读性也降低了很多,并且是不可逆的。
上面的代码只是被 Uglify 了,里面的函数体结构、循环、逻辑判断、运算等都可以看清楚,只不过比较费力。
千万不要把什么字符处理都当成了 “加密”。
我明白你的意思,不过你真的会去读这样的一个函数内容吗……你要说这个是不是标准的 JS 代码,那肯定是,没问题,有函数结构、循环、逻辑判断、运算,但读这样的内容没有意义——这不是 “费力” 一点的问题,将其看做一个黑箱使用就足够了。
更大规模的项目里的代码经过 Webpack 打包,并压缩混淆之后,按照你的说法也确实都是合法可读的 JS 代码,但这种可读性极差的代码没有读的意义,扣出来函数当做黑箱使用就足够了。
抱歉,这里用「加密」一词确实不严谨,当时写的时候是想这是一篇普及性的文章,如果用「压缩」、「混淆」这样的词表达可能会让读者困惑,因为这个地方和全文联系不大,如果专门解释一下压缩混淆这些词语没有必要,就用了直观上方便理解的「加密」一词。
哈哈 当时我在 b 站刷到这些视频也有这个想法
哈哈哈握手握手