

Google Chrome 浏览器的 Developer Tools 无疑是非常好用的一个工具,它有语法着色与最新的 ECMAScript 标准支持,于简洁性上胜
Visual Studio Code 半子,于易用性上胜 Node.js REPL Terminal 一步。因此,在写一些代码片段时,我往往会直接用 DevTools 环境编写代码并测试。
但是,在 DevTools 下编写代码却有一个硬伤,就是数据的保存问题。console 可以将各种变量输出在屏幕上,却无法直接将其保存到本地文件,数据少了还好,数据多了后每次手动保存就很伤。正好最近我写了一个简易爬取京东评论的爬虫,需要批量保存数据,便想找到一个更好的方法。
于是,我决定写一小段 Userscript,为 console 增加一个 save 方法,以一劳永逸地解决这个问题。
代码很简单,如下所示,然后我将解释代码。

这个方法共有四个参数,分别为数据、文件名、JSON 序列化时的 replacer 函数和 JSON 序列化时的缩进。

之后,首先要进行的是对参数的验证。data 肯定是不可或缺的,一旦为空必须报错,不然还保存啥。
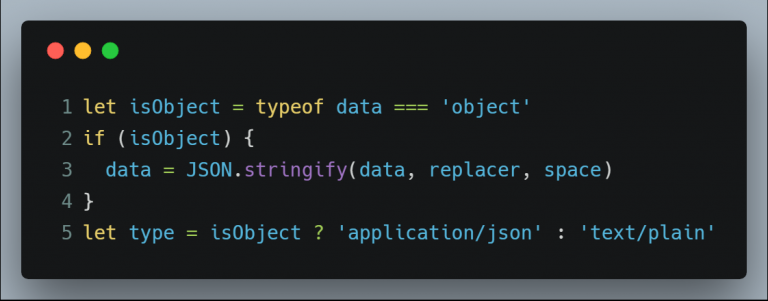
然后就是对 data 类型的判断,如果 data 是原始类型对象(Boolean, Null, Undefined, Number, String, Symbol),那么设定 MIME 类型为 text/plain。如果 data 是其他对象,则一律需要用 JSON.stringify() 转化为 String 再保存。根据 RFC 4627 标准,JSON 数据的 MIME 类型需要设定为 application/json。
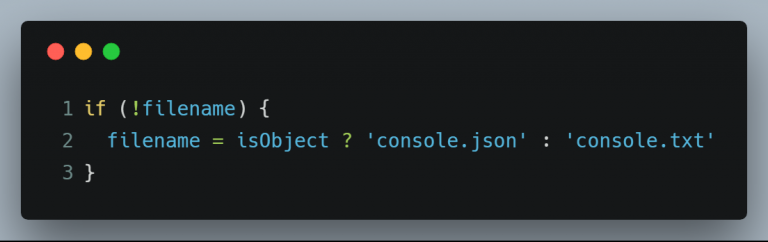
而文件名如果为空也无妨,指定一个默认文件名即可。如果 data 是原始类型对象,默认文件名就保存为 .txt;如果 data 是其他对象,默认文件名就保存为 .json。
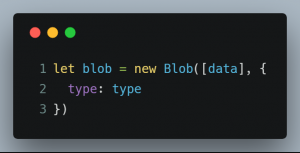
接下来需要构造 Blob 对象以保存数据,Blob 是 binary large object 的缩写,即「二进制大型对象」,在 JavaScript 中,Blob 对象表示一个不可变、原始数据的类文件对象,且 Blob 表示的不一定是 JavaScript 原生格式的数据。此外,File 接口是基于 Blob 的,它继承了 blob 的功能并将其扩展使其支持用户系统上的文件。如果要从其他非 blob 对象和数据构造一个 Blob,则需要用到 Blob() 构造函数。
Blob() 构造函数返回一个新的 Blob 对象。 blob 的内容由参数数组中给出的值的串联组成,语法为:
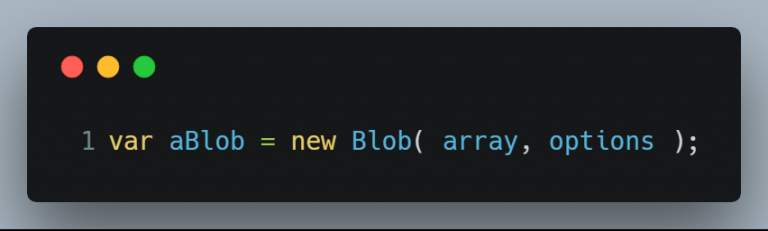
其中,参数 array 是一个由 ArrayBuffer, ArrayBufferView, Blob, DOMString 等对象构成的 Array ,或者其他类似对象的混合体,它将会被放进 Blob。DOMStrings 会被编码为 UTF-8。而参数 options 是一个可选的 BlobPropertyBag 字典。其包含 type 属性,默认值为 "",代表了将会被放入到 blob 中的数组内容的 MIME 类型。
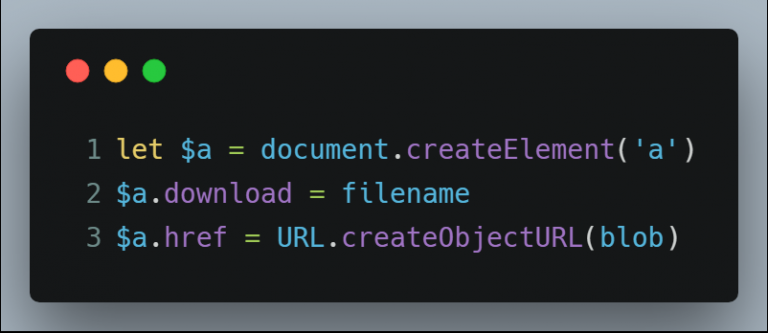
但是,我们是不能直接把 Blob 保存到本地,而是需要借助 HTML 中的 <a> 元素再模拟点击它来达到下载这一目的。因此,在用 document.createElement() 生成元素后,需要设置其 download 属性,强制点击后开始下载而不是打开新页面,再把 href 属性设置为 URL.createObjectURL() 的返回值即可。
URL.createObjectURL() 静态方法会创建一个 DOMString,其中包含一个表示参数中给出的对象的 URL。这个 URL 的生命周期和创建它的窗口中的 document 绑定。这个新的 URL 对象表示指定的 File 对象或 Blob 对象。
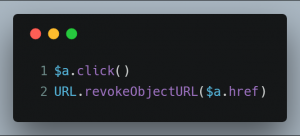
最后,只需要调用 <a> 元素的 click 方法即可开始下载。click 方法可以用来模拟鼠标左键单击一个元素。当在支持 click 方法的元素上使用该方法时(比如元素),会触发该元素的 click 事件。该事件会一直向文档树的上层元素冒泡,也会触发它们各自的 click 事件。但是,冒泡而来的事件会让一个 元素像受到真实的鼠标点击一样执行页面的跳转。
在下载之后,由于这个 Blob 生成的 URL 对象已经完成了历史使命,可以调用 URL.revokeObjectURL() 方法让浏览器知道不再需要保持这个文件的引用了,从而允许浏览器在合适的时机回收掉这个对象。
相关文章

修复「四川大学综合教务系统」只支持 IE9 以下版本浏览器的 Bug(2)
在我发布 修复「四川大学综合教务系统」只支持 IE9 以下版本浏览器的 Bug 这篇文章后,我正常的用这个脚本用了一段时间,然后直到今天,我觉得哪里不太对: 当我想查询一个东西时,我发现这个放大镜根本点不动 =-= 点击后毫无反应,并没有一个窗口弹出来。然后我意识到在之前的文章中,可能我忽视了一些东西,这个 …

修复「四川大学综合教务系统」只支持 IE9 以下版本浏览器的 Bug
注:本文中的代码并不能完全修复在 Chrome / Firefox 等现代化浏览器下打开四川大学综合教务系统的 bug ,为了解决之后我发现的另一个问题,我写了这篇文章的后续更新:修复「四川大学综合教务系统」只支持 IE9 以下版本浏览器的 Bug(2),在这篇后续更新中提供的代码可以完全修复综合教务系统在现代化浏览器下的 Bug 。 …
为 SCU URP 助手增加「计算各种绩点与均分」的功能
期末考试结束了,又到了一年的出分季,若是在过去,算平均绩点和平均分不是什么难事,因为不论是飞扬的绩点计算器还是后来的「We川大」(现川大圈校内通)都很好用。然而,因为教务处这学期的升级改造,帮助了无数学子多年的「川大圈校内通」牺牲了…… 于是我身边的同学们不得不倒退回用Excel或者纸笔计算的原始时代……但作为 …
如何为新版的「四川大学综合教务系统」增加「一键评教」功能
【2020年4月8日更新】这是一篇我在2018年8月写的博文,讲述了如何快速评教的技术细节。但我发现很多人从百度而来,只是为了找一个快速评教的方法的,不太想看实现的技术细节……如果您有这样的需求,我已经制作了一个脚本叫做「四川大学综合教务系统助手」,一直在稳定更新,从旧版教务系统一路适配到新版教务系统的最新版本 …

[译] 如何检测 Chrome Headless(无头浏览器)?
原文链接:https://antoinevastel.com/bot%20detection/2017/08/05/detect-chrome-headless.html 原文标题:Detecting Chrome Headless 原文作者:Antoine Vastel 译者注:自从 Chrome Headless 发布后,各种基于 Chrome Headless 的自动化测试工具、爬虫等项目层出不穷。比起已经停止更新且容易被针对的 PhantomJS、Seleni …